【摘 要】统计分析方法在美国政治学研究中发挥着重要作用。自20世纪初统计分析方法在美国政治学研究中萌芽,至形成政治学研究常见运用统计分析的局面,再至当下大数据时代对研究范式的冲击,它的产生与发展走过了不同阶段,并依然在变化发展中。统计分析方法在美国政治学研究中的运用与发展归功于将统计分析方法与政治现实相结合的学者们的努力。统计分析方法仍在不断改进与更新,以应对内生性问题、数据结构多层问题、模型参数识别问题、统计显著性问题和因果推论难免的假设强弱等问题。在可预见的未来,统计分析方法依然会在美国政治学研究中发挥重要作用,同时也将直面大数据时代大数据分析技术相对于传统统计分析在数据处理方面的优势。
一直以来,美国政治学研究领域对于定量与定性分析方法在研究中的作用争论不休。无论将“美国政治学”视为西方政治学的一个研究领域,抑或是将其等同于西方政治学,这两大研究范式的倾轧都普遍存在,并深刻地影响了美国政治学学科的发展。总体来看,定量分析方法在美国政治学领域中逐渐占据了主导地位。“定量霸权”不是虚名,定量分析方法让学者们在学术成果发表和谋求教职方面都具有一定的优势。以定量分析为基本特性的领域已经形成,即“政治学方法论”。对美国政治的研究是诸多重要的政治学理论的发源。许多从事美国研究的学者强调“美国例外论”(American Exceptionalism),强调美国文化与其他文化的显著差异,或者说美国文化作为个案的重要价值,而这种“例外”也体现在美国与其他西方国家的政治学方法论路径选择的显著区别上。
定量分析方法大致可分为统计分析(计量分析)和形式建模(formal modelling)两种方法。本文将聚焦于前者,基于对美国政治学发展演进中重要的研究方法相关文献的考察,梳理统计分析方法或者说定量分析范式成为美国政治学研究特色的发展历程,以及一些推动统计分析方法在美国政治学研究中得以应用和发展的重要学者的贡献。本文还将从统计分析方法的视角出发,运用典型的研究案例,从数据可视化、多层次模型(multilevel modelling)、贝叶斯分析方法(Bayesian Analysis)、因果推论等具体分析方法切入,结合统计分析方法面对政治学议题存在的问题与学者们更新处理方法的进展,描绘统计分析方法与政治学的碰撞如何数度重新定义美国政治学研究发展的主轴,并结合当下兴起的大数据分析潮流,展望未来统计分析方法在美国政治学研究中的地位。本文试图跳出探讨定性与定量之争的思维定势,旨在对统计分析方法本身在美国政治学研究中的发展过程提供一个跨越历史、涵盖主要研究方法的概览,以期对统计分析方法在美国政治学研究中的作用进行探讨。
美国政治学研究开始使用统计分析方法的具体时间难以考证,但是根据该学科的旗舰期刊《美国政治学评论》(American Political Science Review)发表的论文溯源,至少在20世纪初,美国政治学研究论文中已有初步的统计分析应用——尽管这类论文的发表量非常有限。此后数十年,统计分析方法在美国政治学研究中的发展缓步向前,偶有后撤。
在20世纪的大部分时间里,美国政治学研究之所以能够成功抵御甚至阻止统计分析方法应用的蔓延,主要原因在于当时的统计硬件与软件大幅滞后于统计前沿理论的发展。如果以“刻蚀”来评价统计分析方法对于当前美国政治学研究的影响,那么20世纪早期的政治学人仅能使用基础的统计分析方法,大部分的实证研究甚至局限于使用定性分析方法,以统计为主的定量分析方法一度只是附庸。
20世纪70年代,美国政治学研究领域中开始出现大量的数据采集,数据的积累为统计分析提供了发展的原动力,但是量的增加并未明显地带来质的提升。美国国家科学基金会(National Science Foundation,NSF)支持的美国国家选举研究(American National Election Studies, ANES),为美国政治学研究的一大重点——选举研究——提供了诸多数据基础,促使美国政治学研究开始大量使用统计分析方法。在定量分析得到应用的同时,方法论研究在这一时期变得越来越重要。20世纪60年代中期以后,政治学期刊上关于方法论的文章数量迅速增加。到20世纪70年代中期,《美国政治科学评论》一直是方法论研究成果的主要发表渠道。由美国明尼苏达大学政治学教授约翰·沙利文(John Sullivan)和威廉姆斯学院政治学教授乔治·马库斯(George Marcus)编辑的《政治学方法论》(Political Methodology)于1974年创刊,为政治学统计分析研究的成果提供了发表的平台。然而,在这个时期的大部分时间里,不存在政治学方法论这一领域。这个时期的美国政治学人大多借用其他社会科学(如经济学、心理学、社会学)的统计分析方法。这种间接的统计分析方法移植,囿于缺乏对方法与实际相结合的认识及反思,造成统计方法的引进出现水土不服的情况,导致出现不少统计分析方法应用错误的案例。
20世纪80年代是统计分析方法对美国政治学研究真正意义上的“大举进攻”时期。不论从研究问题的广度、方法应用的深度来看,还是从相关论文的发表量来看,这一时期都可谓是美国政治学研究进展的关键节点,将该领域带向了一条以定量分析为主的路径。随着统计分析方法势如破竹地推进,一场无法逆转的征途,于焉而始。不过,如果没有一些重要人物和事件的出现,统计分析方法在美国政治学研究中就不会有今天的地位。
美国政治学人喜好深究因果,这份偏执注定了他们终将掀起统计分析方法在政治学应用上的革命。这也在一定程度上区分了政治学科与其他社会科学学科。具体来说,美国政治学应用定量分析的学者们通过学会和期刊,努力为新的研究范式开拓空间,提升地位。1983年,以哈佛大学定量社会研究中心主任加里·金(Gary King)教授为代表的一群政治学者,共同倡议成立了推广定量分析方法的学人组织“政治学方法论学会”(Society of Political Methodology, PolMeth)。1989年,以刊登定量分析方法研究与创新成果为主的期刊《政治分析》(Political Analysis)首刊发行。此后,美国政治学人在数据可视化、多层次模型、贝叶斯方法、因果推论等统计方法上屡屡提出新的见解与方法创新,摆脱了长期以来借用其他学科的统计分析方法的窘境;政治学方法论也逐渐成为美国高校政治学专业科系的主要研究领域之一。至此,政治学方法论的发展在经历一个世纪的跌宕起伏后,涅槃重生。
20世纪90年代,积极使用统计分析方法的定量分析路径导向的学者(下文简称“定量学者”)们稳步推进定量研究范式在美国政治研究中的影响。1994年出版的《社会科学中的研究设计》 (Designing Social Inquiry: Scientific Inference in Qualitative Research)一书试图将定量研究与定性研究二者相弥合,列出了进行定性研究的指导方针,论证了定性研究和定量研究的本质都是社会研究,指出它们具有相同的“推理逻辑”。同时,定量学者开始了分析方法的创新。20世纪90年代,定性分析路径导向的学者们强调自身的研究特质的不可替代性,批评定量学者们专注于方法和技术上的细节问题,忽略了政治学者应该关心的实际的重要政治议题。不过,定性分析路径的反扑没有明显效果。而今,《社会科学中的研究设计》已成为美国高校政治学专业的必读教科书,这在某种程度上意味着定量研究范式在美国政治学学生培养体系中的地位。此外,政治学方法论学会的持续发展也意味着这个领域的稳步推进。学者们开始有意识地构建更加多元、包容的学术共同体。以“方法论视野”(Visions of Methodology)论坛为例,它支持政治学方法论研究领域的女性学者参与其中。除了提供一个分享学术工作的论坛外,它还为研究和教学提供了构建学术网络和共享专业指导的机会。
定量学者也面对一定的新情势。21世纪以来,随着计算机科学的发展和人类社会行为的数据留痕的剧增,以及这些数据的分析价值的凸显,大数据时代来临。它奠定了定量研究方法或者说数据驱动的研究方法在美国政治学研究中的主导地位,但也在一定程度上扫除了定量学者的优势,因为既往的模型和统计分析方法不一定能在大数据背景下为他们抢占到优先的学术地位。机器学习等计算机手段因其强大的数据处理能力,挑战着统计分析者在预处理分析对象(即数据)方面的优势,使得诸多常用的模型与统计分析方法难以在数据驱动的时代抢得先机,促使常规调查数据的结果与大数据分析的结果或相互检验或彼此补充。甚至可以说,各种统计分析方法的应用还不根深蒂固,诸多分析方法还处在学者的持续争论中,大数据时代和新的分析手段可能将过去定量分析的优势一扫而空。
二、引领统计分析方法运用的美国政治学人
美国政治学人的投入让许多前沿的统计分析方法在社会科学研究中取得突破性进展。诸多统计分析方法在政治学的应用和发展之所以主要由政治学者推动,很大程度上是因为政治学者喜欢问“为什么”,即为何这么做?原因是什么?学者乐于深挖现象背后的逻辑并进行合理论证,这就引出了对于厘清逻辑的需要,即什么因素导致什么现象?什么因素和什么现象有明显的关系?或者说,到底是“鸡生蛋”还是“蛋生鸡”?总之,政治科学学者们对因果的深究推动了统计分析方法的进步。
至于为什么政治学人在不断创新,这是因为在现实的政治问题中,不乏统计模型设计中被忽视或者高估、低估的要素。美国政治的复杂性一直引发着学者们深耕。比如,美国政治中的选举问题就牵涉美国政治的方方面面,学者们需要用各种高阶方法解决相关的数据分析问题。也可以说,政治议题的复杂性在一定程度上催生了美国政治学者开发和创新统计分析方法。
许多美国政治学人在推动统计分析方法成为美国政治学研究的主流方法的过程中功不可没。本文选择兼顾代际差异,透视统计分析方法在美国政治学研究领域的演进轨迹,但限于篇幅,不在此一一列举重要人物的学术贡献,仅介绍几位主要学者及其贡献。
耶鲁大学政治学、计算机科学和统计学教授爱德华·塔夫提 (Edward Tufte)可以被称为美国政治学研究中的数据可视化之父。他跨界政治学与统计学,在数据可视化方面的影响力已经超越了学科的限制,他的四本专著更被数据科学家们奉为圭臬。在推进统计分析方法应用于美国政治学研究的过程中,他最大的贡献是在早期统计分析手段不足以支持更复杂、更进阶的分析时,提出应多利用并列图形的可视化手段帮助政治学者识别数据中呈现的多元信息,并有意识地利用复杂的图形代替复杂的建模。比如,针对多结构数据,用图形呈现各州选民支持民主党还是共和党,以便轻松地识别在大量数据背后,民众对不同党派支持度的具体差异。
纽约大学政治学教授亚当·舍沃斯基(Adam Pzeworksi)提倡以变量分析取代案例分析方法,倡导政治学者用变量思维将政治学研究对象与其他变量的关系清晰化。他以关注经济发展与民主化的关系闻名,研究领域横跨经济学和政治学两大学科,把经济学计量方法大量运用于政治学研究中。比如,他将马尔科夫转换模型(Markov Switching Model)用于政体转型研究,该模型解决了在时间序列横截面数据中二元因变量存在序相关(serial correlation)的问题——亦即前期因变量与当期因变量高度相关,使得在进行回归分析时会违反残差项互为独立的假设。
普林斯顿大学政治学教授克里斯托弗·艾肯(Christopher Achen)是政治学方法论学会首任主席。他积极地把回归分析方法引入政治学研究中。他的《解读与运用回归》(Interpreting and Using Regression)一书介绍了美国政治学研究如何应用统计方法中的回归分析,有助于帮助学者们应对多元变量情况下,当单个自变量解释因变量时不知如何控制其他自变量的问题。此外,他还关注选择性偏差 (selection bias)和生态谬误(ecological fallacy)等问题。他指出,在政治学研究中,研究者在样本选择上容易出现各种偏差;研究者在推论分析时,也容易混淆研究的分析层次,以全概偏,此即为“生态谬误”(ecological fallacy)。
纽约大学政治学教授纳撒尼尔·贝克(Nathaniel Beck)开发了估计时间序列和面板数据的统计量——面板校正标准误(panel corrected standard errors)。随着美国政治学研究数据的积累,逐渐形成诸多时间序列数据。比如,跨较长时段分析美国多年的选举调查数据,必然要处理较大的样本量,而一般的回归分析可能会忽略面板之间的相关性,即时间段的前后影响,这就需要恰当的时间序列分析方法。如果说有政治学者在研究方法上有典型创新,则非纳撒尼尔·贝克莫属。
加里·金教授在政治学方法论方面的影响相当广泛。20世纪90年代他与人合著的《社会科学中的研究设计》一书旨在推动定性研究方法的规范化,该书确定统计分析的因果推论原理为分析政治问题的法则。他的另一部著作《统一政治学方法论》对定量研究方法也起到类似作用。他将“生态推论” (ecological inference)方法用于从总体数据中推断出个人行为,回应了克里斯托弗·艾肯当初对生态谬误问题的提醒。他的“辅测定锚法”(anchoring vignettes)方法有助于实现跨文化调查的可比性,减少调查问卷在测量不同国家地区的不同的人对某一概念的理解时存在的误差。他的短文《复制,复制》开启了政治学领域的数据共享运动。他指导的“哈佛数据库”(Harvard Dataverse)项目极大地带动了政治学领域的研究数据公开与共享。学者们可以将其发表的使用统计分析方法的论文的数据和代码上传至数据库(https://dataverse.harvard.edu),以供其他学者检验、学习和寻求合作。
哥伦比亚大学统计学与政治学教授安德鲁·格尔曼 (Andrew Gelman)也是横跨政治学与统计学界的学者。他擅长贝叶斯分析方法和多层次分析模型的应用。他的统计学专业背景和数十年从事数据分析的经验,使得他对于数据具有异于常人的敏锐度,许多政治学方法论学者经常向他咨询数据分析上的问题。他常常在博客 (andrewgelman.com)上发表短文,讨论社会科学统计实践中的问题和趋势。他的工作让记者和公众更容易理解统计数据分析在政治科学中的应用。比如他的《红州、蓝州、富州、穷州:为什么美国人如此投票》(Red State, Blue State, Rich State, Poor State: Why Americans Vote the Way They Do)一书,改变了美国人关于党派投票模式的政治迷思,改变了学者们对选举和美国政治的思考方式,并通过大量使用数据可视化手段,使统计数据中多层次的信息对公众具有更广的可理解性。他的《贝叶斯数据分析》(Bayesian Data Analysis)是当代学习及应用贝叶斯理论及方法的必读教科书。
美利坚大学政治学、数学与统计学教授杰夫·吉尔(Jeff Gill)是横跨政治学、数学、统计学和高阶统计分析方法的集大成者,以及美国政治学顶级刊物《政治分析》主编。他致力于发展贝叶斯多层次模型(Bayesian Hierarchical Model)和非参数贝叶斯模型(Bayesian Nonparametric Model),在统计计算特别是马尔科夫链蒙特卡罗(MCMC)工具方面,有着深厚的专业知识。社会科学或医学科学中最复杂的贝叶斯模型需要复杂的、精密的计算工具,以有效地估计分析者感兴趣的参数。杰夫·吉尔是这些统计和计算技术方面的专家,利用它们为生物医学和社会科学的深入研究做出了贡献。
以上学者几乎皆跨越了统计分析方法植入美国政治学研究的全过程,属于经历重重变迁的老一代重要定量学者。对比新一代和老一代学者们在学术训练上的差异,有助于理解统计分析方法在美国政治学领域中的地位,并可由此管窥政治学定量方法学术训练的变化和美国政治学者的时代特征。
政治学方法论学会第一任会长克里斯托弗·艾肯的学术成长道路,可以说是统计分析方法训练在政治学领域中早期运用与发展演进的“活化石”。在他攻读博士学位的20世纪60~70年代,全美只有屈指可数的政治学系有统计和数据分析方面的专家任教。1968年,克里斯托弗·艾肯在耶鲁大学选修了一门由经济学系老师讲授的面向政治学系本科生的研究方法课程。老师的观点远远超前于当时的时代,至今都适用于政治学统计分析中,但对于严谨的推论的追求在当时并没有市场。在计量经济学理论的指导下进行实证研究,根据数据特点和研究需要进行创新,是二十几岁的克里斯托弗·艾肯所做的工作。当他于1972年寻求教职时,没有政治学方法论领域的职位。在那个年代,运用统计分析方法的政治学文章凡是用到回归分析,就会被视为关于“方法论”的论文。克里斯托弗·艾肯有幸在罗切斯特大学找到教职后,于1975年开始讲授有关贝叶斯推论的课程,之后其使用贝叶斯分析方法的文章在《美国政治科学期刊》(American Journal of Political Science)上得以发表。碍于分析软件有限,且当时相对艰深的贝叶斯统计分析路径难以普遍化,克里斯托弗·艾肯讲授的课程持续时间不长。在一段时间之后,美国政治学中统计分析方法的发展才逐渐步入正轨。
在新一代美国政治学者中,哈佛大学政治学教授今井耕介(Imai Kosuke)较具有代表性。今井耕介于2003年从哈佛大学获得政治学博士学位,他的研究领域属于政治方法论,他专注于发展统计分析方法及其在社会科学研究中的应用。他广泛研究用实验和观察数据进行因果推断的统计分析方法的发展和应用,曾任普林斯顿大学“统计与机器学习”项目的创始主任。不难想象,由他这一批学者所训练的新一代政治学学者们,必然会在统计分析技术和计算机技术方面拥有所长。目前在美国政治学博士就业市场中,在政治学方法论上有所造诣者,比如统计分析能力佳、会软件编程语言甚至能开发软件分析包进行研究方法创新者,受到更多青睐。可见,统计分析方法深深嵌入美国政治学,随着一代代学者的复合型发展,这种嵌入将持续深入下去。
统计分析方法的运用与数据及其特征密切相关。统计分析方法得以施展的基础是数据,没有数据,一切统计分析方法都是空壳;反言之,没有合适的统计分析方法进行处理,从数据中获取的信息可能存在谬误。在过去一个世纪中,美国政治学界对统计方法的运用,围绕着如何正确解码数据中的信息而展开的,具体体现在四个方面。
(一)数据信息呈现方式
美国政治学者以表格的方式呈现数据信息的偏好持续到21世纪初。时任哥伦比亚大学政治学博士候选人的乔纳森·卡斯特莱茨(Jonathan Kastellec)和爱德华多·莱昂尼(Eduardo Leoni)统计2006年社会科学五大类顶级期刊中的论文后发现,超过60%的数据信息采用了表格的呈现方式,其中大约90%被用以呈现统计分析结果。尽管政治学可视化专家爱德华·塔夫提早在20世纪80年代就不断呼吁和提倡以数据可视化的方式呈现复杂的政治数据,但囿于一般绘图软件费用昂贵、不易操作和出版发表范式的固化,美国政治学界一直未能将数据可视化广泛应用。
21世纪初,美国政治学界出现了研究成果发表范式的改革。27学者们接续爱德华·塔夫提所倡议的主张,认为数据可视化可以更具体地展示以数值表形式存在的政治学定量数据,因为图表展示不仅方便对数据中包含的信息进行可视化和分析,而且使人们对其呈现的结果有相对更强的印象,因为对大多数人来说,视觉记忆比语言或听觉记忆更持久。
数据可视化改变政治学研究成果发表范式的关键步骤之一,当属安德鲁·格尔曼推动使用“秘密武器”(secret weapon)取代表格,呈现回归分析(regression analysis)的结果。他建议学者使用下图呈现系数的点估计(point estimates)(实心点)和系数的标准误(standard errors)构成的95%置信区间(confidence intervals)(图中横线),这个图形有别于传统表格呈现的方式,可以让读者直观且迅速地发现哪些变量具有统计显著性(statistical significance)。以下图的回归结果为例,已婚和拉美裔两个变量的95%置信区间皆横跨0值参照虚线,说明这些变量的系数估计值在很大概率(95%)上与0值无差异。这意味着该变量对于因变量的影响为零,即不具有统计显著性。
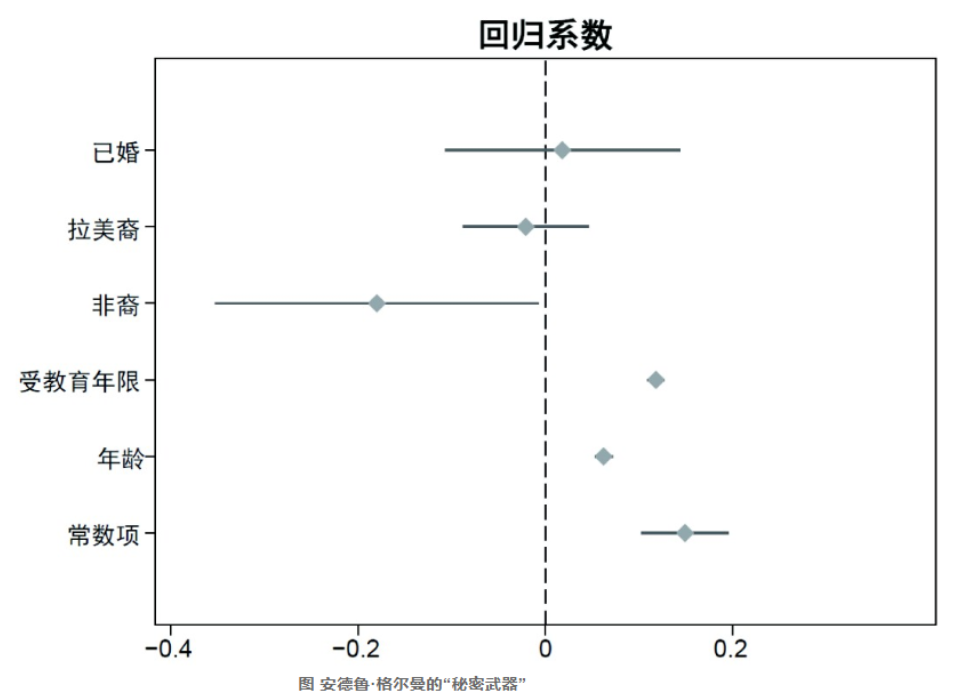
安德鲁·格尔曼对“秘密武器”的成功推广,与其推广使用多层次回归模型估计美国选举数据高度相关。随着政治学者开始大量使用多层次回归模型进行数据分析,期刊论文版面无法继续使用表格的方式呈现大量的参数估计值。以美国51个州十年的选举模型估计为例,最为朴素的多层次回归模型需要呈现至少51(州)笔参数估计值,稍微复杂的模型至少需要呈现51(州)×10(年)=510笔参数估计值。因此,研究人员必须思考如何使用数据可视化的方式更有效率地呈现大量的参数估计值。在实际需求的推动下,加上开放源代码的R软件的普及应用使花费在绘图软件上的成本降低,数据可视化在21世纪第一个十年广泛地为政治学者所采用,并成功地改变了包含统计分析的研究成果的发表范式。
(二) 数据多元多层结构
政治学研究所使用的数据,一般来说在结构上多元多层。例如美国政治学研究常用的美国全国选举调查数据,包含了数十年、数次选举、51个州、不同地区等多层结构,大量多元的变量(如性别、宗教、教育程度、候选人支持度、政府满意度、政治信任度、政治价值观等)皆属于定类变量。分析如此多元多层的数据依赖的是进阶的统计分析方法和模型,然而它们的学习成本高,配套的软件和软件包不普及。美国政治学者投入了大量精力研究这一分析方法上的问题。
自1994年加里·金等人所著的《社会科学中的研究设计》一书问世以来,书中倡议使用大样本进行数据分析的理念让越来越多的美国政治学者思考在原有数据结构上加入时间和地理维度,以扩大研究数据的样本量。以美国总统选举选中民投票研究为例,假设分析以州为基本分析单元,则样本量仅为51州;如果考虑自20世纪40年代以来的20次选举(时间维度扩容),则样本量增至51(州)×20(年)=1020个;再考虑以州以下行政区域为基本分析单元(地理维度扩容),美国共有3142个郡,则样本量可增至51(州)×20(年)×3142(郡)=3204840个。
在数据中加入时间这个维度,即成为时间序列数据,是多层数据结构的一类。当时任教于麻省理工学院的政治学者道格拉斯·希布斯 (Douglas Hibbs) 于1973年首度将AR(1)模型运用到对总统候选人支持度的分析中,其模型原理是使用因变量的滞后一阶(即变量的前期观测值)解决时间序列数据自相关的问题。该方法虽然在很大程度上解决了序相关的问题,但由于时间序列数据中的因变量与其滞后一阶往往高度相关,因此使用滞后一阶变量估计因变量后,模型余下的方差(variance)往往不足以支撑其他理论上具有意义的自变量对于该因变量存在统计意义上的解释力。直至20世纪末,美国政治学研究仍未能很好地解决序相关的问题,因为序相关系数属于不能识别的参数。2010年,时任普林斯顿大学政治系助理教授(现为清华大学国际关系学系教授)庞珣运用贝叶斯分析方法,对于自相关系数AR(p)进行建模估计,解决了序相关系数识别问题。
如果在时间维度之外再考虑地区或国别等地理因素,那么多层结构的数据便构成了政治学者(尤其是国际关系研究学者)常用的时间序列横截面数据 (time series cross sectional data)。1995年,纳撒尼尔·贝克等人在研究发达国家的政治制度与社会福利支出的关系时,研发出面板校准标准误统计量,以便在处理时间序列横截面数据进行普通最小二乘法 (ordinary least squares) 回归分析时,调整低估的系数标准误。相较于其他计量经济学的方法而言,该方法容易应用,因此广受学者青睐。但是该方法对于数据质量的要求较高,即要求平衡的面板数据结构(例如,每一个州需要相同的且连续不断的时间观测值)。使用面板校准标准误的研究一旦忽略这一要求,极易产生谬误。
时任耶鲁大学政治学系教授(现为哥伦比亚大学政治学系教授)唐纳德·格林(Donald Green)等人使用固定效应(fixed effect) 模型重新检验过去50年里美国政治学者发表的关于国际关系的研究结果后发现,多数研究结果都是错误的。以往使用时间序列横截面数据的国际关系研究,忽略了数据结构多层的事实,而采用全池化(pooled)回归分析(纳撒尼尔·贝克等人开发的面板校准标准误也属于采用全池化回归的分析步骤),导致所得系数和标准误产生偏差。唐纳德·格林等人的研究结果发表后,纳撒尼尔·贝克等人随即著文反击,称在国际关系研究中使用固定效应模型进行分析会顾此失彼,运用固定效应模型所产生的其他统计问题甚至更为严重。纳撒尼尔·贝克等人在文末指出,随机系数效应模型(random conefficients model)是更为合适的分析方法之一。
21世纪初,美国政治学者围绕如何建模以估计时间序列横截面数据争论不休。有鉴于此,《政治分析》于2007年出版专刊,讨论各种统计分析方法企图解决的使用时间序列横截面数据所面临的三大问题,即面板异质性(heteroskedasticity)、时间自相关(temporal correlation)以及序相关。其中,以安德鲁·格尔曼为师的几位政治学者提出,贝叶斯多层次回归模型在分析时间序列横截面数据时,其原理是对数据多层结构分别建模估计,并使用贝叶斯先验解决参数无法识别的问题,这是当前分析该类型数据最优的统计分析方法。
(三)统计参数识别问题
由于受到统计参数识别问题的局限,美国政治学界自20世纪70年代以来引入的几个重要的进阶统计分析方法和模型在运用层面进展缓慢。除了上文提及的时间序列分析中序相关系数无法识别的问题外,内生性(endogeneity)问题所使用的联立方程(simultaneous equations)中的回归系数、定类变量回归模型中的潜变量(latent variable)、多层次回归模型中的超参数(hyperparameters),也都存在参数识别的问题。
内生性问题是指解释变量和被解释变量相互作用,相互影响,互为因果。以描述数学方程的方式表达,即在联立方程中(数个回归模型)的一些变量既可以在其中几个方程的右边项成为解释变量,又可以其他方程的左边项成为因变量。因此,这些回归模型中的一个或多个解释变量会与回归的随机扰动项(random error,或称残差项)相关,从而违反了普通最小二乘法回归的基本假设,导致所估计的回归系数有偏差。此外,在不借助其他统计手段的情况下,该联立方程有无穷解(不存在唯一解),亦即回归系数这个统计量无法识别。
内生性问题普遍存在于政治学研究之中,但一直到哥伦比亚大学政治学教授罗伯特·埃里克森(Robert Erikson)关于“在任优势”(incumbency advantage)的论文发表,才正式走入美国政治学研究的视野。罗伯特·埃里克森教授重点研究了候选人背景因素作为自变量如何影响作为因变量的选举获胜机率。他指出,美国选举研究在分析候选人获胜因素时,忽略了自变量和因变量互为因果的问题:候选A在前期国会选举中当选代议员后,因为在任优势,往往可以在下次竞选时连任成功。这种情况在分析纷繁复杂、往往有多种因素作用于政治现象的现实政治时,难以避免。从统计分析本身的角度而言,两个变量建立因果联系的前提之一是时间的先后顺序,即解释变量在先,被解释变量在后,否则很容易犯因果倒置的错误。
密歇根大学政治学教授约翰·杰克逊(John E. Jackson)首度使用结构方程模型解决美国选举研究中的内生性问题。他假设人们的议题立场及其对政党的认同和对政党立场的评价之间的高度关联对于投票决定具有内生性,从而对选举过程中各议题所起的作用以及人们对各政党在不同议题上的立场的评价,做出了新的解释。之后,应对内生性问题的分析方法发展到使用工具变量来解释,比如以募兵抽签制度为工具变量,分析参与越南战争对美国人健康和收入的影响。
工具变量解决内生性问题的原理是:使用工具变量估计存在内生性的解释变量,并用这个估计值置换该解释变量为新的解释变量,最后使用新的解释变量与因变量进行回归,得到不具内生性问题的回归系数估计值。工具变量虽然可以解决内生性问题,但是工具变量分析方法存在信度(reliability)和效度(validity)的问题。选择合适的工具变量必须保证两个条件:第一,工具变量和关键的解释变量必须存在一定程度的相关性;第二,工具变量和因变量之间不能存在过高的相关性。后者即排他约束假设 (exclusion restriction assumption),也是工具变量方法中最为重要的假设。简言之,这两个条件假定因变量仅受到解释变量的直接影响,而不会受到工具变量的影响。
现实中要找到同时满足这两个条件的工具变量并不容易,因为与关键解释变量高度相关的工具变量(数学上可以将其视为等同于该解释变量的变量),很大概率上会与因变量高度相关(因为解释变量与因变量高度相关)。2001年,唐纳德·格林等人统计了1985年以来发表在美国政治学三大期刊上的论文,发现超过80%的学者选择不说明在其研究中排他约束假设是否被满足,或仅依赖既有的理论或过去的相关研究结果进行间接的佐证;只有10%左右的论文选择使用实验方法或者回归检验的方式证明排他约束假设被满足。这种选择性忽视深刻地反映出美国政治学界的研究需要更严谨、更科学地对待研究中的变量存在内生性的问题。
美国选举研究引入的复杂统计模型也存在参数无法识别的问题,进而影响到相关方法的广泛应用。加州理工学院政治学教授迈克尔·阿瓦雷兹(Michael Alvarez)和纽约大学政治学教授乔纳森·纳格勒(Jonathan Nagler)在1994年至1998年间发表了一系列论文,分析美国选民投票的抉择。有别于其他仅仅分析两党竞争场景下选民投票抉择的研究,他们采用多项概率回归模型(multinomial probit regression model)估计美国选民如何在超过三个分属不同政党的总统候选人之间做出投票抉择。阿瓦雷兹等人撰写此文时,尚未有合适的软件可以操作多项概率回归模型,必须自行编程处理。这个应用层面的限制阻碍了多项概率回归模型在美国政治学研究中的广泛应用。多项概率回归模型从潜变量模型推导而出,基本假设是选民投票抉择(y)可以映射成为一个连续型的潜变量(y*),当这个潜变量积累到一定阈值时,就会发生选择的改变。处理多项概率回归模型时会遭遇余数参数不可识别的问题,为了解决这个问题,必须进行一连串的参数转换,计算上非常复杂。1999年,密歇根大学政治学与统计学教授凯文·奎因 (Kevin Quinn) 等人使用贝叶斯方法处理多项概率回归模型,解决了处理该模型在计算上的复杂性,加之今井耕介开发出R软件多项概率回归模型包,才降低了应用多项概率回归模型的门槛。
如果说进阶统计模型中参数识别问题阻碍了美国政治学研究统计分析方法的应用,作为解决之道的贝叶斯方法则给美国政治学研究带来了方法上的跳跃。随着贝叶斯方法的使用,许多进阶模型中的难点被克服,美国政治学界开始探索将这些方法应用于各项研究的更多可能性。例如,范德堡大学政治学教授乔舒亚·克林顿 (Joshua Clinton)和宾夕法尼亚大学政治学教授约翰·拉宾斯基(John Lapinski)使用项目反应理论(item response theory) 模型,重新检视了1887年至1994年美国国会各个法案立法的重要性。这有别于过去类似研究仅依赖个别学者构建的单一数据库分析,并且,结合贝叶斯方法还利于解决项目反应理论模型参数无法识别的问题。他们成功地合并了几个数据库,做出更为客观的法案立法评价。又如,哥伦比亚大学政治学系教授杰弗里·拉克斯(Jeffrey Lax)和哥伦比亚大学政治学系副教授贾斯汀·菲利普斯 (Justin Phillips)使用多层次回归模型以及事后加权的手段,通过自变量间复杂的交叉效应分析美国各州对支持同性恋的公众舆论的政策回应性,也是得益于贝叶斯方法的使用。通过解决大量的模型参数设定问题,他们得以获得对于政策回应性更为精确的估计值。
贝叶斯方法迟迟未能在美国政治学界广为应用的原因,主要是该方法的数学运算复杂,对计算机运算硬件的要求更高。贝叶斯方法真正得到广泛应用是在1990年后,肇因于学者们突破了数学运算上的难题,以及计算机硬件升级,相应的计算机软件和统计套件(如WinBUGS、OpenBUGS、JAGS、R2WinBUGS、R2jags、rjags、MCMCpack等)也如雨后春笋般出现。值得注意的是,投入这些软件开发的不少是政治学者。其中安德鲁·格尔曼和杰夫·吉尔是推广贝叶斯方法在政治学研究中应用的重要学者,两人分别撰写的贝叶斯方法教科书成为高校贝叶斯方法课程的必读教材。
美国政治学者在论文发表和教学上青睐贝叶斯方法的原因在于先验(prior)的使用,即它与既有学科的研究方法和原理相通,但它也因此备受争议。贝叶斯方法中的先验是指研究者先于演算前掌握的对某个未知参数的既有知识。通常这个知识可以是过往的研究结论,也可以是相关研究专家的推论和猜测。结合先验分析的方式与社会科学学者做研究时梳理并参考既有研究文献获得知识的习惯,不谋而合。但是批评贝叶斯方法的学者认为,先验的使用过于主观,会污染和影响客观的科学研究。
(四)统计显著性问题
2018年,美国政治学顶级期刊《政治分析》在其网页的来稿须知中宣告,今后投稿该刊的论文中应用回归分析的表格不再需要汇报p值(P value)来证实其分析的统计显著性。该刊由此成为所有学科中第一个向p值这个统计量发难的期刊。美国统计学会(American Statistical Association, ASA) 曾在2016年发文,针对统计分析中p值代表统计显著性的合理性和合法性进行检讨。近年来,各学科期刊逐渐掀起对统计分析应用p值的反思,要求使用更为严格的p值标准,甚至应该废除以p值为统计显著性的参考统计量。值得注意的是,早在其他学科之前,政治学界已对于p值开启了在其他学科鲜见的改革。究其原因,除了政治学人骨子里有对问题深究到底的精神外,也与几位重要的政治学方法论方面的学者有关。他们可以说是推动p值革命的重要先锋,其中安德鲁·格尔曼和杰夫·吉尔更是早在2018年之前就发表了一系列论文,检讨p值应用的合法性。他们都是贝叶斯统计学派的应用者。在应用贝叶斯方法的学者看来,由于p值可以通过给定的强先验获得,所以它作为统计显著性的唯一参考标准不足为证。
纵观具有鲜明特色的统计分析方法在美国政治学中的演进历程,自20世纪80年代起,统计分析方法开始在美国政治学研究中发挥越来越大的作用。如今,凡是提及美国的政治学研究,几乎所有研究主题下都很容易看到含有数据和图表的学术论文。但是,需要注意的是,就整个政治学研究方法而言,依然存在诸多争论尚待时间沉淀。学者应该理性地看待统计分析方法,在考虑到其优点和可能存在的缺陷的同时,将统计分析方法运用到研究中。
一方面,统计分析方法服务于审慎的因果推论,以清晰的数据呈现对变量之间关系的分析结果,展现一个变量在多大程度上影响到另一个变量,以避免“一刀切”的结论,为现实的政治分析乃至政策制定提供参考;而且,鉴于几乎不可能在政治现实中拥有如实验室般的理想环境来进行研究,需要使用统计分析方法控制一些变量,并在模型里包含可能对变量关系有所贡献的变量,以得到近乎如自然科学实验室般的理想条件。这有助于证明变量之间的关系,对于孜孜不倦地追求政治研究科学化的美国政治学者而言必不可少。
另一方面,政治学中的统计分析必然面对数据多元多层结构特性、统计参数识别问题和统计显著性问题的限制,这就需要学者的学术自觉与审慎。统计分析的数据结果诚然提供了研究的透明性和分析的可靠性,但事在人为,一个重要前提是,使用统计分析方法的学者要有足够的知识,能合理地处理数据并使用模型。而且,学者们必须小心“垃圾进,垃圾出”(garbage in, garbage out)。也就是说,如果在分析中加入了错误的或者有问题的数据,则无法得到正确的结论。特别重要的是,统计分析方法产生的结果需要经得起复制(replication) 的检验,而可复制性的前提是研究者愿意共享数据。研究的可复制性在近年来越来越受到重视,但依然面临学者共享意愿的桎梏。渥太华大学政治学副教授丹尼尔·施托克梅尔(Daniel Stockemer)等人对三份政治行为主义导向的刊物进行分析后发现,许多作者仍然不愿意公开分享他们的数据,只有略多于一半的作者表示愿意共享数据,并且其中大约有25%的文章没有提供整理好的数据或代码,使研究结果无法得到复制和再检验。
如今,统计分析方法在美国政治学界的应用方兴未艾。同时,大数据时代已然来临,一些美国政治学者的注意力开始转移到机器学习、人工智能上。2009年,以美国东北大学政治学、计算机科学与信息科学教授大卫·拉泽尔(David Lazer)为首的15位学者联合署名在著名期刊《科学》(Science)上发表的《计算社会科学》一文,56被普遍认为标志着计算社会科学这一新型交叉学科的诞生。这篇文章明确指出人们身边已经出现新的数据机遇,其最大的特点就是大数据的涌现。数据是一切统计分析的基础,没有数据则难有学术先机。美国政治学研究也受到这股风潮的影响,大量政治学者投身于对大数据的研究和相关方法的学习。
对于定量学者而言,大数据是机遇,但也可能是挑战。定量导向的美国政治学研究必然基于数据,数据的可获取性和特征会调动定量导向性学者敏感的学术神经,新数据和新方法的出现足以让学者们兴奋起来。新获得的大数据可能进一步验证或证伪过去小数据的研究发现,而未来更多、更全面的数据可能又会推翻立足于大数据的分析结论,抑或为之辩护。早期政治学统计分析方法的应用借用统计学、经济学等学科的分析模型对有限的、可获取的数据进行处理,而今在大数据浪潮下,数据分析亟待运用计算机学科的知识应对纯人工或普通统计分析技术难以突破的技术壁垒。可以预见的是,新一代美国政治学者会越来越擅长于计算机分析技术,甚至优秀的政治学者可能像优秀的计算机科学学者一样优秀,涌现出复合型学者。
如前所述,统计分析这一鲜明特色是美国政治学研究追求科学性的体现。政治科学为证明其科学性,尤其重视对政治行为和现象解释的因果推论,统计分析方法本身是为更好的因果推论服务,因果推论的论述与定量分析密不可分。相较于大数据时代,以往的因果推论原则往往致力于满足“必要非充分性条件”,而今则转变为满足“充分非必要条件”。定量学者在其擅长的因果推论中,常用一些变量解释另一些变量,采取干预的方式来发现因果机制(causal mechanism),解释某些变量很重要或者就是被解释变量的原因。在统计分析方法中,本文前述的数据信息呈现方式、数据多元多层结构、统计参数识别、统计显著性等方面的问题亦尚未完全解决,学者们一直围绕相关问题开展持续的研究,或者在分析方法上形成学术自觉,在研究成果中说明研究结论成立的各项前提假设。建立在诸多前提假设基础上的种种因果机制,似乎都适用于解释特定的政治现象,但这种解释往往是局部的,或者说其解释范围的扩大很有难度,因为在选择变量或建立假设时或多或少地有所选择或忽视。每一个政治要素和过程都可能改变所有情况。如果学者想尽可能多地解释政治现象,就不能仅依赖一个因果机制。
可以预见的是,数据将层出不穷,统计分析方法在美国政治学研究中的地位也将依然稳固。然而,如果被数据绑架,那么可能会看到越来越多统计分析方法与数据合谋“撒谎”的荒唐现象。严谨的研究设计仍然是政治学里发掘变量间关联及作用机制的黄金准则。
【注 释】
(1)一般来说,政治学在美国高校分为美国政治、国际关系、比较政治、政治理论、政治学方法论等不同研究领域。
(2)葛传红:《西方政治学界对于“定量霸权”的反思与批判》,载《国际政治研究》,2019年第1期,第117~141页。
(文清整理)



